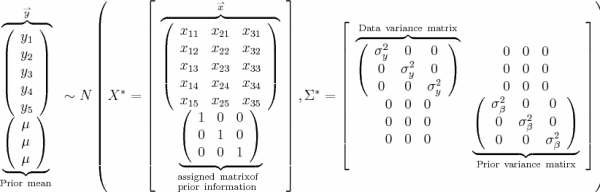
One implication behind the gibbs sampler is that it is actually
using prior information as the aumented data. So if we have no information on prior (uniform prior), the variance compoent in the augmented covariance matrix will be bunch of zero's. And it is just the same as regression model.
However, if we do have information on prior, that is elicit prior, the prior can serve as a tool to identify beta's where the beta's in the original from is either colinear or unidentifiable.
 See Andrew Gelman, 2004, Bayesian Data Analysis, ch 14 for details.
See Andrew Gelman, 2004, Bayesian Data Analysis, ch 14 for details.



No comments:
Post a Comment